You have an idea, a hook, maybe even a full set of lyrics. The problem is everything that comes after: finding the right groove, matching a vocal vibe, arranging a believable chorus lift, and turning a rough concept into something that actually feels like a complete track. That gap between “words on a page” and “a song you can share” is exactly where Diffrhythm AI becomes interesting. In practice, it does not feel like a novelty button. It feels closer to a fast, structured way to explore musical directions when you do not want to open a DAW, hunt for stock music, or stitch short clips together.
What follows is a grounded walkthrough of how it works, what it does well, where it can surprise you, and where you should expect to iterate.
- The Core Promise, in Plain Terms
- How Diffrhythm AI Works (Without Over-Claiming)
- What You Can Control (And What You Cannot)
- A Comparison Table That Highlights the Practical Differences
- The Before-and-After Bridge (Why It Feels Different in Use)
- Where It Fits in a Creator’s Workflow
- Credibility, Context, and a Calm View of the Field
- Practical Limitations That Make the Experience More Believable
- The Bottom Line
The Core Promise, in Plain Terms
Diffrhythm AI is designed around a simple workflow: you provide lyrics and a style prompt, and it generates a full song that includes both vocals and accompaniment. Instead of producing only an instrumental bed or requiring you to combine multiple generations, it aims to output a coherent “song-shaped” result in one pass.
That matters because many music generators still behave like sketch tools. They produce short segments, loops, or mood pieces that sound good in isolation but require manual work to become a track with verses, choruses, and development. Diffrhythm AI’s promise is not perfection on the first try. It is speed-to-structure.
Why Speed Changes the Way You Create
If a tool takes minutes per attempt, you tend to settle. You accept a “close enough” intro, or you stop exploring alternate chorus energy. When the iteration cycle is fast, your behavior changes:
- You try multiple styles for the same lyric without emotional fatigue.
- You adjust the lyric phrasing to guide rhythm and pronunciation.
- You audition different “musical identities” for the same message (melancholic, cinematic, upbeat, intimate) and keep the best one.
In other words, speed is not just convenience. It becomes a creative lever.
A Realistic First-Run Experience
In a typical first session, you may notice a pattern:
- Your best results usually come from lyrics that have clear sections (verse, chorus, bridge) and consistent line lengths.
- Style prompts that specify mood and instrumentation often guide the output more reliably than broad genre labels alone.
- The second or third generation is frequently stronger than the first, because you start “speaking the model’s language” with more precise prompts and cleaner lyrical cadence.
That is not a flaw; it is the normal shape of working with generative systems. You are not ordering a song. You are steering a search.
The Small Input Tweaks That Make a Big Difference
When you want the model to stay stable, micro-edits matter:
- Keep chorus lines shorter and punchier than verse lines.
- Use repeated phrases intentionally; repetition signals hooks.
- Avoid overly dense syllables in one line if you want clearer vocal intelligibility.
- Put stage directions inside brackets only if you want structural guidance, not lyrical content.
A Useful Metaphor for What’s Happening
Think of Diffrhythm AI less like a “music vending machine” and more like a fast audition room. Your lyrics are the script. Your style prompt is the casting direction. Each generation is a new performer interpretation, sometimes surprisingly aligned, sometimes off-key, often revealing a direction you did not know you wanted.
How Diffrhythm AI Works (Without Over-Claiming)
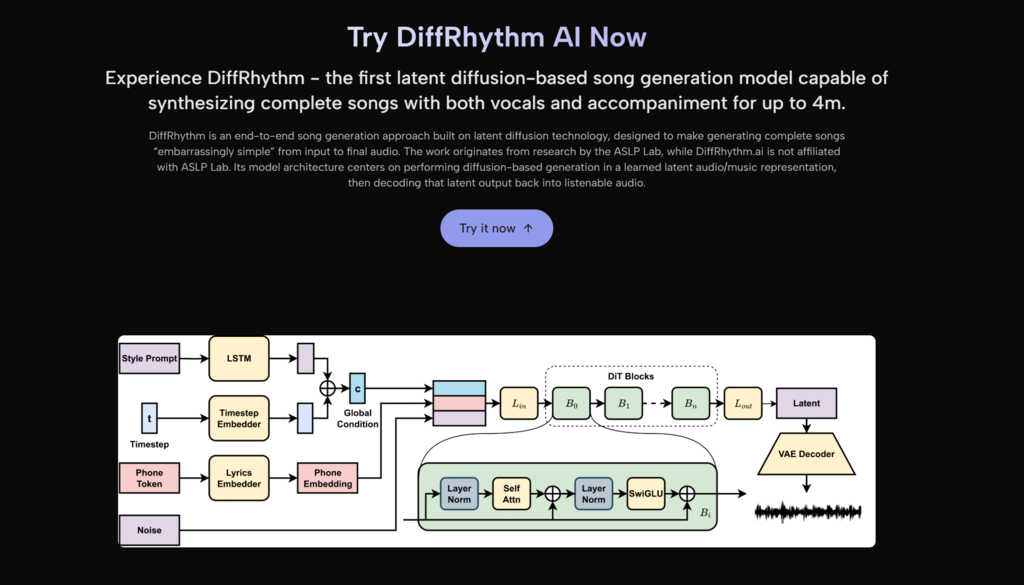
Diffrhythm AI is associated with a latent diffusion approach to song generation. In general terms, diffusion models create outputs by progressively refining noise into a structured signal under conditioning inputs (here, lyrics and style). The DiffRhythm research line reports that this method supports fast, non-autoregressive generation of full-length songs, rather than slow token-by-token audio continuation.
You do not need to memorize the architecture to benefit from it. What you should take away is practical: the system is built to produce complete, song-length outputs quickly, with vocals and accompaniment aligned, rather than forcing you to assemble a track from fragments.
What You Can Control (And What You Cannot)
Diffrhythm AI is controllable in a “producer-like” way, but not in a “mixer-like” way.
What You Can Guide
- Mood and energy (gentle, triumphant, tense, playful).
- Genre direction (pop, rock, lo-fi, EDM, cinematic).
- Instrumentation cues (piano-driven, guitar-led, synth-heavy, strings, acoustic).
- Vocal character cues (soft, powerful, airy, gritty), depending on what the system exposes in the interface.
- Song structure, indirectly, through your lyric layout.
What Still Takes Iteration
- Exact melody control (you are guiding, not composing note-by-note).
- Perfect pronunciation for every uncommon word or name.
- Consistency of vocal timbre across every attempt.
- Mix decisions (how loud the vocal is versus drums, etc.), unless your plan includes stem extraction or vocal removal features.
This is the honest trade: you gain speed and accessibility, and you accept that the “last 10 percent” may require multiple generations or post-work if you have strict production standards.
A Comparison Table That Highlights the Practical Differences
Below is a pragmatic comparison, focused on how creation feels rather than how marketing copy sounds.
| Comparison Item | Diffrhythm | Typical Alternatives |
| Output shape | Aims for full song with vocals and accompaniment together | Often short clips, loops, or separate vocal/instrument generations |
| Iteration speed | Designed for rapid attempts, encouraging exploration | Slower runs can discourage experimentation |
| Control method | Lyrics + style prompt steer structure and vibe | Some tools favor vague prompts or require multi-step workflows |
| “Song-ness” on first try | Often closer to a complete track form | Frequently needs manual arrangement or stitching |
| Learning curve | Prompting and lyric formatting matter, but no music theory required | DAWs require production skills; clip tools require assembly effort |
| Best use case | Turning lyrics into multiple viable musical directions fast | Stock libraries for quick background music; DAWs for precise production |
| Limitations you will feel | You may need several generations for the exact vibe or clarity | Clip tools may never reach full-song coherence without heavy work |
The Before-and-After Bridge (Why It Feels Different in Use)
Before tools like this, lyric-first creators often had two options:
- Spend time learning production tools, or hiring collaborators.
- Settle for generic backing tracks and hope the audience focuses on the message.
After you add Diffrhythm AI into the workflow, a third option opens up: you can test how your lyrics behave inside different musical worlds quickly. That is not just convenience. It changes decision-making. You can decide whether your chorus wants a major lift, a half-time drop, or an intimate acoustic pocket by hearing it, not imagining it.
Where It Fits in a Creator’s Workflow
Diffrhythm AI tends to fit best in one of three roles:
- Draft-to-direction: create multiple versions to choose the “identity” of your song.
- Content pipeline: generate short, consistent brand tracks for videos, intros, or social posts.
- Collaborative handoff: bring an AI-generated demo to a musician or producer as a clearer starting point than a text lyric sheet.
This is also where expectations matter. If you expect a chart-ready master in one click, you will be disappointed. If you expect a fast, usable demo engine that can occasionally produce genuinely compelling takes, you will likely find it valuable.
Credibility, Context, and a Calm View of the Field
Generative music is moving quickly, and the space includes diffusion-based approaches, transformer-based approaches, and hybrid systems. If you want a broader, neutral framing of limitations and open problems in generative AI music (beyond any single product), one useful external reference is the 2025 ISMIR Transactions discussion “The Limits of Generative AI Music” (Morreale, 2025), which outlines why evaluation, control, and musical meaning remain hard problems even as output quality improves.
That context helps set the right mental model: these tools are powerful creative accelerators, not replacements for taste, direction, or revision.
Practical Limitations That Make the Experience More Believable
To make your results more consistent, it helps to acknowledge a few real constraints up front:
- Prompt sensitivity: small changes in style wording can shift arrangement and vocal delivery more than you expect.
- Lyric density: lines with too many syllables can reduce clarity or force awkward rhythm.
- Variance: the same prompt can produce noticeably different interpretations; you may need multiple generations.
- “Good enough” is a choice: if you are publishing commercially, you may still want light editing, leveling, or stem-based tweaks depending on your plan.
In practice, the most productive mindset is to treat each generation as a candidate. Keep the ones with strong hooks, discard the ones that miss your message, and refine inputs like a producer giving clearer direction.
The Bottom Line
If your creative bottleneck is turning lyrics into something you can actually hear, Diffrhythm AI is compelling because it shortens the distance between concept and audible reality. It is not magic, and it is not always effortless. But when you approach it as a fast exploration tool, it can turn a stalled lyric into multiple “finished enough” musical directions in the time it used to take to find one acceptable track. That speed gives you something rare: momentum, with options.